如何理解一種語言?
小時候學習中文,會背誦課文詞彙的注釋,在作業簿練習這個詞的寫法。到了國中時期學英文,面對像天書般的英文文章,會把不懂的單字圈起來,拿出字典查這個字的意思。為什麼這樣做?
因為,詞彙是語言的最小單位。
然而,中文有一個特殊現象,就是「詞」和「詞」之間沒有邊界,整句串起來像條鎖鏈,不像英文有空格將每個字斷開。所以,若要理解一篇中文文章,必須先學會斷詞,而要學會斷詞,必須先知道這是一個詞、以及這個詞的意思。否則可能會產生這種令人「難過」的情況:

圖│網路趣聞

圖│研之有物
 「自然語言」有多自然?
「自然語言」有多自然?
![]() 我們先來了解「自然語言」的定義,與「程式語言」有什麼差別。
我們先來了解「自然語言」的定義,與「程式語言」有什麼差別。

圖│研之有物
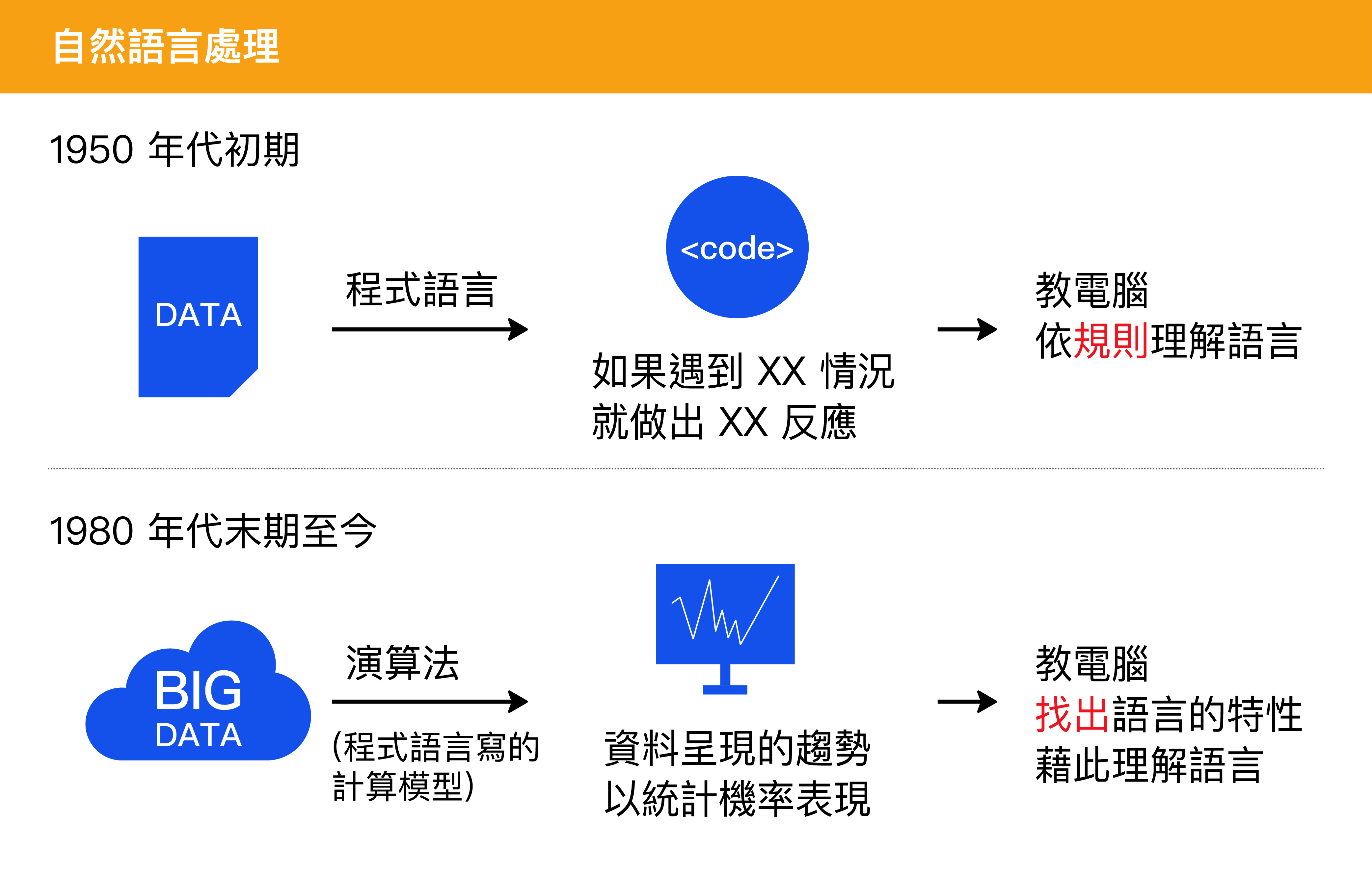
簡要來說,程式語言是人類為了與計算機溝通,而設計的人工語言;而自然語言的自然,是相對於「人工」語言的「自然」,換句話說,自然語言是人們溝通時自然地發展出來的語言。「自然語言處理」的目標,就在於讓電腦理解、或是運用人類語言。
如何教電腦學會一種語言?
![]() 若要讓電腦理解人類的語言,以中文來說,分成兩步驟:
若要讓電腦理解人類的語言,以中文來說,分成兩步驟:
第一步是斷詞、理解詞;第二步則是分析句子,包含語法及語義的自動解析。
自然語言處理透過這兩個步驟,將複雜的語言轉化為電腦容易處理、計算的形式。早期是人工訂定規則,現在則是讓機器自己學習。
早期的方式是基於一套詞彙資料庫,用程式語言寫好人工訂定的規則,讓電腦依指令做出反應。但這種人工方式不可能包含所有語言的歧異性,例如,當同樣的詞在不同上下文產生不同意思,就會和原本的人工規則相互牴觸。
1980 年代末期,自然語言處理引進機器學習 (Machine Learning) 的演算法,不再用程式語言命令電腦所有規則,而是建立演算法模型,讓電腦學會從訓練的資料中,尋找資料所含的特定模式和趨勢。我們實驗室——中研院的「中文詞知識庫小組」團隊——就是利用機器學習的演算法,讓電腦學會從訓練的資料中,自動歸納出語言的特性。
圖│研之有物
訓練電腦處理自然語言,需要什麼樣的資料?
![]() 我們團隊成員涵蓋中研院語言所、資訊所的研究人員,所以我們也充分利用這兩個領域的專長。
我們團隊成員涵蓋中研院語言所、資訊所的研究人員,所以我們也充分利用這兩個領域的專長。
首先,語言學家為九萬多個中文詞彙定義了完整的語法、以及語義表達方式,並且也標明詞彙之間的關係,例如:「蝴蝶」和「昆蟲」具備「前者是後者的一種」這樣的詞彙關係;「醫生」和「病人」具備「前者醫治後者」這樣的詞彙關係。這樣的表達構建了中文的知識圖譜,我們稱為「廣義知網」。
詞彙的語法、語義定義完畢後,接下來我們就依這些規則,大量分析文章中的每個句子、每個詞彙的語法和語義,並將分析的結果記錄下來 ,這就是「語料標注」的工作。這些標注的語料,提供給電腦系統進行機器學習,讓電腦學會自動歸納、找出語言的語法以及語義。
我們的想法是,既然語言學家已分析了某些語言結構的邏輯,那麼基於這些存在的語言學知識來教電腦歸納出語言的特性,是一種相當自然合理的方式。
只是我們大多數情況下,不會直接教電腦學會語言學上的規則,給它一條魚,不如給它一支釣竿。我們是給電腦看語言學家分析完成的大量結果,由電腦利用機器學習而自動歸納得到 「規則」, 並以參數的方式(請別擔心,一定是人們看得懂的形態),儲存在資訊學家所設計的模型當中。這種電腦自動學出來的模型,能夠很好地解決語言歧異性,也不會有人工寫死規則的問題。
電腦可以認識所有「詞」嗎?
![]() 語言的詞彙組合無窮無盡,不可能將所有詞都收進資料庫中訓練電腦。當電腦面對與時俱進的新詞,例如「郭書瑤」、「班奈狄克·康柏拜區」、「漫撕男」、「非典」,電腦就無法辨識、理解這個詞。
語言的詞彙組合無窮無盡,不可能將所有詞都收進資料庫中訓練電腦。當電腦面對與時俱進的新詞,例如「郭書瑤」、「班奈狄克·康柏拜區」、「漫撕男」、「非典」,電腦就無法辨識、理解這個詞。
通常未知詞可分為幾種類型:可能是人名、可能是複合詞、或可能是專有名詞。
我們團隊將「中文斷詞」這個工作,切分成下圖 7 個步驟,每個步驟都是一種演算法模組,處理一種特別的問題。
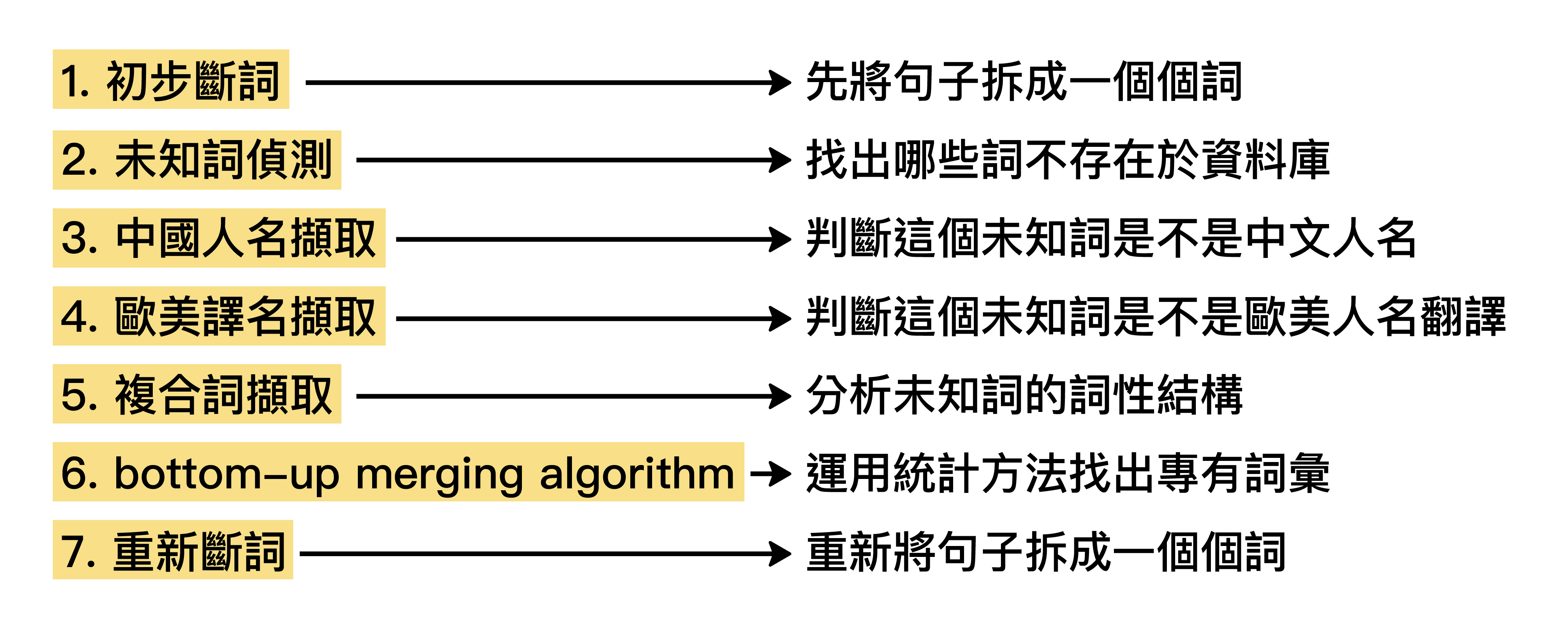
圖│〈未知詞擷取作法〉,作者:馬偉雲
教電腦擷取人名,是相對單純的工作,因為人名的結構有跡可循。
中文人名通常是三個字、或兩個字,甚至能參考百家姓、某一年考生的所有名字來建立資料庫,例如「慧」、「婷」常出現在女性人名中,而「雄」這個字常用在男性人名中。從統計機率來看,有些字則是不可能作為人名使用。人名的前後文也會有一些暗示訊息,例如「XXX 表示…」、「 XXX 做了…」、「執行長 XXX」。當電腦分析訓練用的文章資料,自己找出這些規律,電腦就能學會判斷某些未知詞是否為人名。
此外,「複合詞」也是舉不勝舉的未知詞來源。
中文的複合詞,由相當隨性的詞性結構組成,例如「趣味性」,隨意置換字尾,就變成「趣味感」或是「趣味化」。複合詞的字差一點點,就能延伸許多詞意,這讓電腦需辨識的詞彙量變得無比龐大。這部分透過前輩們的研究,漸漸找出複合詞的組成邏輯,整理在中央研究院漢語平衡語料庫(標記了一千多萬個詞彙),也整理出常用詞首、詞尾字資料庫。
目前斷詞系統中的複合詞主要是針對「名詞複合詞」,但其實我們也在「動詞複合詞」上也累積了不少研究。舉一個實例來說明,例如「開聊」和「聊開」:

圖│〈現代漢語複合動詞之詞首詞尾研究〉,作者:邱智銘、駱季青、陳克健
從語言學的角度,動詞是句子的核心,也是最重要的中心語。「開」這個字有著動詞中心語的起始功能 (inchoative),然而放在詞首、詞尾不同位置會產生些微差異。
除了人名、複合詞,新聞或網路文章還會看到許多新創的專有詞,例如:非典( SARS 重症非典型肺炎的簡稱)、河蟹(意指封鎖、掩蓋負面消息)。這類專有詞可以透過 bottom-up merging algorithm (合併字詞演算法)處理。
以「河蟹」為例,透過合併字詞演算法分析新聞、網路文章等資料,電腦會發現:通常「河」後面就是「蟹」,「蟹」前面就是「河」,「河蟹」兩個字一起出現的統計機率蠻高的,而且整組詞意無法單用「河」或「蟹」的各別字意取代。因此,電腦就會判斷「河蟹」最可能是個專有詞、並做出斷詞。
此外,就算是字典當中已經有的詞彙,有時候仍然會有不同斷詞的情況,我們必須根據上下文決定哪一種斷法才是正確的。例如:「努力才能成功」的「才能」應該切分為兩個詞彙:「才」和「能」,語義接近英文的 “to make”;而「他的領導才能很突出」的「才能」是一個詞彙,不可切分,在此表達英文的 “ability” 的意思。

圖│馬偉雲說明
電腦理解「詞」了,那「句子」呢?
![]() 學會斷詞、並理解個別的詞義之後,下一步我們就要使電腦學會理解整個句子的意思。例如「張三打李四」和「李四被張三打」,兩個句子雖然句型不同,但是語義卻是一樣。
學會斷詞、並理解個別的詞義之後,下一步我們就要使電腦學會理解整個句子的意思。例如「張三打李四」和「李四被張三打」,兩個句子雖然句型不同,但是語義卻是一樣。
我們怎麼表達句子的語義呢?答案是透過「結構樹」。

圖│馬偉雲說明
我們將每個詞彙集結成片語,再把每個片語標記上它所扮演的語義角色 (semantic role)。「張三」在兩個結構樹中都是「打」的發動者 (agent) 的角色,而「李四」都是「打」的對象 (goal) 的角色。如此一來,透過包含語義角色的結構樹,我們可以得知這兩個句子擁有相同的語義。
先透過人工訂好結構樹的表達,下一步就是要利用機器學習,使電腦能夠自動針對每一句產生出正確的結構樹。歷年來,中文詞知識庫小組從中央研究院漢語平衡語料庫抽取句子,經由電腦初步剖析成結構樹,再加以人工修正檢驗,共整理了六萬多個中文句結構樹圖,標注了各個中文句的語法以及語義角色,這些就形成機器學習的訓練材料,使得電腦剖析結構樹的工作越做越好。
自然語言處理的進展到了這裡,斷詞有解,句子結構及語義有解,但還有另一個難題──曖昧不清的指代詞。
寫作時為了避免某些詞重複出現,會使用別的指代詞,像是「他」、「某某職稱」等等。用句子舉例,「張三打李四,他很痛」,覺得痛的人究竟是誰?除了考量語句結構,也需基於常識和上下文來理解。
若要教電腦理解指代詞、處理「指代消解」(Coreference Resolution) 的問題,有兩種方式。一種較傳統,用程式語言寫好所有判定的人工規則,好處是較精準,壞處是有其侷限,因為列舉的規則不可能對應至世間所有指代情形。另一種是機器學習的方式,當電腦分析所有訓練文章的上下文發現:幾乎都是被打的李四感到痛,「他 = 李四」這個相關性的機率即為最高,進而做為電腦日後判斷的準則。
自然語言處理的方法,有因「深度學習」而改變嗎?
![]() 近年來蓬勃發展的深度學習 (Deep Learning),提出了另一種方法來教電腦表達詞彙。這種方法是將詞彙轉換為「詞向量」,也就是 Word Vector 或稱 Word Embedding,作法是讓電腦閱讀大量文章,利用前後文的統計特性,慢慢學習出每一個詞彙的詞向量,不必利用任何語言學知識。
近年來蓬勃發展的深度學習 (Deep Learning),提出了另一種方法來教電腦表達詞彙。這種方法是將詞彙轉換為「詞向量」,也就是 Word Vector 或稱 Word Embedding,作法是讓電腦閱讀大量文章,利用前後文的統計特性,慢慢學習出每一個詞彙的詞向量,不必利用任何語言學知識。

圖│研之有物(資料來源│馬偉雲)
舉例來說,傳統的符號學中,「蝴蝶」、「瓢蟲」、「爬」是不同的三個詞彙。但改成用向量思考,「蝴蝶」和「瓢蟲」的向量距離就會比較近,「蝴蝶」和「爬」的向量距離就會比較遠,隨著訓練的文本越來越多,電腦可以自動調整各個詞彙的向量,解決訓練資料不足的問題,並提升電腦的抽象化思考。
運用「詞向量」的好處是,很多時候針對特定的自然語言處理任務,訓練資料是不足的。因為許多字詞的語義,在人類語感上明明意思很接近、可以相通,但對機器來說,詞彙符號(也就是字元)不同,就是截然不同的詞彙,造成各個詞彙在訓練資料的統計佔比相當低,無法得到足夠信心水準的分析結果。
然而,訓練過程中,若我們以「詞彙向量」作統計,在向量空間上,有些字詞間的向量很靠近,團結力量大,就會發現相近的詞彙向量在訓練資料的統計佔比大幅提升,解決了訓練資料不足的困境。同時,詞彙向量在深度學習的模型之中,被視為可修改的參數,所以也具備了語義(詞彙向量)自動調整的能力。
You shall know a word by the company it keeps.
John Rupert Firth 這句古老的語言學名言,恰巧能說明「詞向量」的思維。其實每個詞就像一個人,若想了解這個人,可以觀察他身旁的人是什麼模樣,也就是物以類聚的概念。
我們團隊目前嘗試結合「傳統詞彙符號」與「詞向量」,共同從事自然語言處理的任務、以及教電腦表達知識。傳統詞彙符號的好處,在於提供清晰的解釋與穩定的應用,而詞向量可以解決訓練資料不足的困境,並且提供語義(詞彙向量)自動調整的能力。這兩者的長處互補,結合起來具有很高的學理價值、更多應用突破。
自然語言處理,有什麼用?
![]() 其實,自然語言處理的用途,已經悄悄在我們身邊幫上許多忙。
其實,自然語言處理的用途,已經悄悄在我們身邊幫上許多忙。
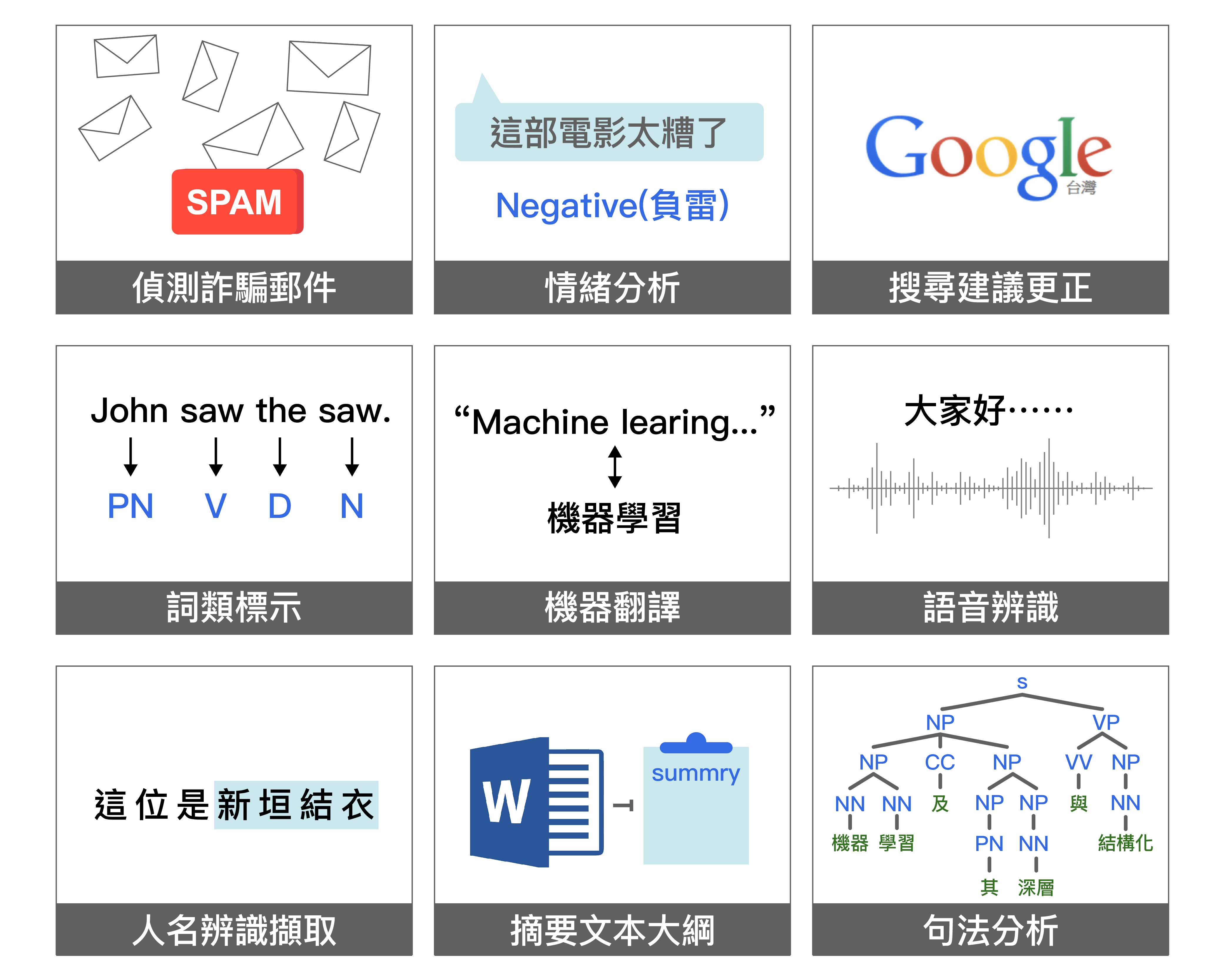
圖│研之有物(資料來源│李宏毅演講)
例如,運用「摘要文本大綱」的能力,電腦可以擔任助手,幫助連睡覺時間都快沒有的醫生閱讀最新的醫學報告、篩選醫學文獻,找出眼前這位病患的病徵,可能跟哪些疾病相關、或是服用某種藥物可能有哪些副作用。像是 2017 年台北醫學大學,就導入 IBM 的 Watson for Oncology (人工智慧治療輔助系統) ,協助醫師診斷致病機制複雜的癌症。
現在許多人遇到地震、颱風等災害,第一步是上社群媒體發佈消息,例如哪裡的大樓倒了、哪些親友失聯了、各地需要捐助多少物資等等。若運用自然語言處理,讓電腦自動搜集、分析這些社群媒體的文本,就能幫助整合災情、協助救援。
另外,輿情分析、聊天機器人等熱門應用,其基礎也需要先讓電腦理解人類所使用的語言,掌握其中的句法結構、分析字裡行間的情緒,才能統計輿情、或讓機器人做出適當的聊天回應。
自然語言處理,是時間的累積。從民國 75 年到現在,中研院資訊所和語言所合作建立許多語料庫和線上系統,我們很歡迎公家機關和公益團體無償使用,也歡迎有需求的單位來討論合作方式。
為什麼會對「讓電腦擁有語言能力」感到著迷?
![]() 我很幸運十幾年前有機會進入這個領域,那時候很驚嘆:怎麼會有一種學問,可以把「語言學」和「計算機科學」結合在一起。
我很幸運十幾年前有機會進入這個領域,那時候很驚嘆:怎麼會有一種學問,可以把「語言學」和「計算機科學」結合在一起。
語言是很複雜的現象,語言也代表人類的智慧,像是我們的思緒、意識,很多都是透過語言來展現。
1999 年那時候,我在交大電腦科學與資訊工程系碩士班是做語音辨識,那時候我只懂「聲音訊號」的處理,很好奇「語言」這塊怎麼讓電腦了解。當時和中研院接觸,知道中研院做了很多自然語言處理的工作,例如蒐集大量語料,用計算機的方式把語言的統計特性找出來。
後來我來到中研院服國防役,從研究助理做起,跟著陳克健老師研究中文的斷詞切分,也逐漸發現原來理解語言有非常多面向,包含:語音、詞彙本身的學問、語法結構(這句話怎麼說才合理)、語義解讀(這句話是什麼意思),還有「語用」,也就是什麼時候講這句話、為什麼要這樣講。
2006 年之後,我到美國哥倫比亞大學的電腦科學系讀碩博士,除了博士論文是做機器翻譯,也在那裡的實驗室研究電腦的 Q&A 系統:問電腦問題,讓電腦讀過一堆文獻後回答,這些文獻資料包含中文、英文和阿拉伯文,三種語言混合運用。因為國防上的需求,美國國防部需要透過電腦幫助,了解這些文本在說什麼。
有些對人工智慧發展的疑慮是,在近年電腦深度學習的運算過程中,不知道為什麼會這樣得出結果、難以控制電腦。但現在有一種發展方向,叫做「可解釋人工智慧」(Explainable AI),明確了解電腦運算過程,藉以優化表現、降低人們擔憂。舉例來說,當 IBM 的 Watson for Oncology 建議醫生要開刀治療病患,醫生也得知道電腦分析文本的過程、為什麼會下這個決策,不是電腦控制人而已。
至於之前曾傳出 Facebook 的 AI 對話失控,其實是過度擔憂。
因為這只是 Facebook 工程師教電腦學會「談判」的過程中,電腦自動將對話內容表達地極簡再極簡、能通就好。
當初唸書時,「自然語言」很冷門,跟別人說也不知道這是什麼東西,因為那時人工智慧在商業上還沒有實際應用,和我們的生活還很遙遠。選擇這個領域並不是因為有遠見,只是基於好奇參與、覺得這很有趣,過程就看到自然語言處理 (NLP) 蓬勃發展至今。